
The idea to write this topic came to me after a production system failure we experienced recently. Failures are unavoidable. Nothing is worse than having your business application down without the proper way to mitigate the issue. That’s exactly how the catastrophe may develop, i.e. due to the somebody's negligence, lack of experience, bugs sneaked into the software, natural disaster, hacker attack, intermittent failures irrelevant to a target system, etc. Disasters do not happen out of the blue. There is a series of chain events contributing to the catastrophe, creating a 'snowball effect'. The inefficiency in decision making leads to a 'blame game' where the situation rolls out of control very quickly. Imagine you're having the issue that requires quick and efficient resolution and the business (and overall, the company's reputation) is at stake. What would you do?
Let's begin with some theory from Harvard School of Business.
As Prof. Amy Edmondson states, the wisdom of learning from failure is incontrovertible. The companies that handle it well are extraordinarily rare. Some teams devote many hours to after-action reviews, postmortems, and alike. However, it became evident that in many cases, it leads to a minimal or no real change. Every individual knows that admitting failure means taking the blame. That is why so few organizations have shifted to a culture of psychological safety in which the rewards of learning from failure can be fully realized. A good question is: if people aren’t blamed for failures, what will ensure that they try as hard as possible to do their best work? This concern is based on a false dichotomy. In actuality, a culture that makes it safe to admit and report on failure can—and in some organizational contexts must—coexist with high standards for performance. The unfortunate consequence is that many failures go unreported, and their lessons are lost.
Reasons for failure
A sophisticated understanding of failure’s causes and contexts will help to avoid the blame game and institute an effective strategy for learning from failure. Although an infinite number of things can go wrong in organizations, mistakes fall into three broad categories: preventable, complexity-related, and intelligent.
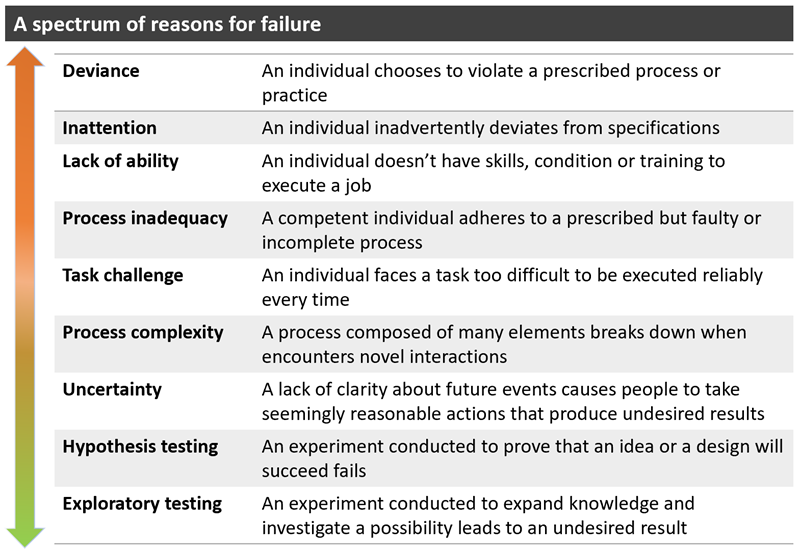
Figure 1. Reasons for failure
Most failures in this table can indeed be considered “bad.” They usually involve deviations from the spec in the carefully defined processes of high-volume or routine operations in manufacturing and services. With proper training and support, employees can follow those processes consistently.
Failures are unavoidable
In complex organizations like aircraft carriers and nuclear power plants, system failure is a perpetual risk. Serious failures can be averted by following best practices for safety and risk management, including a thorough analysis of any such events that do occur, small process failures are inevitable.
In a sense, the year 2017 was indicative of system outages and related costs. The 2017 ITIC Cost of Downtime survey finds that 98% of organizations say a single hour of downtime costs more than $100,000. More than eight in 10 companies indicated that 60 minutes of downtime costs their business more $300,000. And a record one-third of enterprises report that one hour of downtime costs their firms $1 million to more than $5 million. Interestingly, the average cost of a single hour of unplanned downtime had risen by 25% to 30% since 2008 when ITIC first began tracking these figures.

Figure 2. Companies that suffered major outages in 2017
BA, of course, wasn’t alone for having suffered financially for having its systems down. There were also United Airlines (200 flights delayed for 2.5 hours, thousands of passengers stranded or missed connections), Starbucks (couldn’t accept any payments but cash in affected stores), Facebook (millions of users offline and tens of millions of ads not served during the 2.5 hours of downtime), and WhatsApp (600 million users affected, 5 billion messages lost). And when Amazon S3 went down in March 2017, it collectively cost Amazon's customers $150 million.
Detecting failure
Spotting big, painful, expensive failures is easy. But in many organizations, any failure that can be hidden as long as it’s unlikely to cause immediate or obvious harm. The goal should be to surface it early before it has mushroomed into a disaster. Don't be confused, as the missing Unit and Integration tests in your project indicate the quality control issue. At the same time, when people say 'disaster' or 'resiliency' or 'recovery', these belong to the way the system is being operated in the production environment (so refer to an operational instruction, deployment guide or run-book for a particular system).
Being a consultant, a part of my job was to conduct IT/Projects/Architectural assessments and do you know how many times I saw a proper DR documentation in place? Not a single time!
Having a proper DR documentation that explains the process at the event of a disaster is good, but not enough, obviously (judging from the table above). So, what else can organizations do to cut the risk of downtime? The answer is: break your system on purpose!
One of the brightest examples of DR drills comes from the biggest companies like Netflix, where the team has come up with an engine to inject failures into the software's normal operations called 'Chaos Monkey'. The idea is not new, and it entails the theory of chaos engineering many companies approached and adopted. Here’s where chaos engineering comes in: you know you have these potential points of failure and vulnerabilities. So why wait until there’s a problem? Imagine attempting to break your systems. On purpose. Before they fail on their own. Because that is what chaos engineering does.
By triggering failures intentionally in a controlled way, you gain confidence that your systems can deal with those failures before they occur in production.
Engineering a failure
First and foremost, there’s the rapid shift to the cloud. A full 70% of companies have already moved at least one application to the cloud, according to IDC. Then there’s the rise of microservices. Most enterprises are developing their software today on a Microservice Architecture. Applications are built as small and independent but interconnected modular services. Each service runs a unique process meant to meet a particular business goal. For example, one microservice might track inventory levels of products. Another might handle serving personalized recommendations to customers. Then there are all the web servers, databases, load balancers, routers, and more that must work together to form a coherent whole. This is not easy! (I'd say, nothing related to Microservices Architecture is easy). Yes, sure, businesses can do things with software that simply weren’t possible before, but these new capabilities come at a price.
All computers have limits and possible points of failure. By injecting a system with something that has the potential to disrupt it, you can identify where the system may be weak and can take steps to make it more resilient. Here’s where chaos engineering comes in: you know you
have these potential points of failure and vulnerabilities. So why wait until there’s a problem?
Critical to chaos engineering is that it is treated as a scientific discipline. It uses precise engineering processes to work. Four steps, in particular, are followed:
- Form a hypothesis: Ask yourself, "What could go wrong?”
- Plan your experiment: Determine how you can recreate that problem in a safe way that won’t impact users (internal or external)
- Minimize the blast radius: Start with the smallest experiment that will teach you something\
- Run the experiment: Make sure to observe the results carefully
- Celebrate the outcome: If things didn't work as they should, you found a bug! Success! If everything went as planned, increase the blast radius and start over at #1
- Complete the mission: You’re done once you have run the experiment at full scale in production, and everything works as expected.
The goal of chaos engineering is to teach you something new about your systems’ vulnerabilities by performing experiments on them. You seek to identify hidden problems that could arise in production prior to them causing an outage.
Some examples of what you might do to the hypothetic system when performing a chaos engineering experiment:
- Reboot or halt the host operating system. This allows you to test things like how your system reacts when losing one or more specified units
- Change the host’s system time. This can be used to test your system’s capability to adjust to daylight saving time and other time-related events
- Simulate an attack that kills a process
- Take more radical methods like halting the cluster node (in Kubernetes) or simulating a DDoS attack (using BoNeSi for layer 3 and 4 attacks and ddosim for layer 7 attacks)
Naturally, you immediately address any potential problems that you uncover with chaos engineering.
Chaos engineering is also good for disaster recovery (DR) efforts mentioned before. If you regularly break your systems using tight experimental controls, then when your systems go down unexpectedly, you’re in a much better position to recover quickly. You have your people trained, and you can respond more promptly. You can even put self-healing properties in place so you can continue to maintain service with minimal disruption. Using chaos engineering for disaster recovery is also important for compliance reasons. Sarbanes Oxley II (SOX 2) as well as industry- or geography-specific regulatory mandates require that you can recover quickly from a disaster.
When we're talking about SLAs (Service Level Agreement) in the clouds like MS Azure, that's what meant by guaranteed availability throughout a year:

Table 1. Guaranteed availability
Make no mistake! Chaos engineering doesn't mean randomly breaking things. The reason this is not an optimal approach is that “random” is difficult to measure. You are not approaching the problem using experimental methods. The idea behind chaos engineering is to perform thoughtful, planned, and scientific experiments instead of simply random failure testing.
What if an issue has already happened?
- First and foremost, stay calm (even though it may seem obvious). The issue's not resolved by panicking and bringing all hands on deck
- Follow DR instructions (the bullet points below belongs to them)
- Run through the services logs, look at the diagnostics reports, review the health statuses of the services in the cloud
- If you're not sure this is an intermittent or a full-blown outage, narrow-dowd the focus of your investigation to specific service (by switching on/off the services, re-pointing the traffic etc.), review the services status report (like this one for MS Azure: https://status.azure.com/en-us/status)
- Have your Infrastructure-as-a-Code and respective scripts handy, so you could re-deploy quickly
- Fire a Sev.A ticket to a cloud support team
- Keep all the stakeholders informed about every step of the issue resolution. This is probably one of the most important aspects of the issue resolution. People have to know that the problem is being resolved.
Wrapping up
As this topic uncovered, there are two different, and the same time-related aspects of fault handling: technical and managerial. While technical aspect can be managed by accepting different tactics, like designing for resiliency and HA, chaos engineering etc., the managerial is a bit more sophisticated (and refers to psychological safety at the working environment). Ironically, a shared but unsubstantiated belief among managers that there was little they could do contributed to their inability to detect the failure. Postevent analyses suggested that they might indeed have taken fruitful action. But clearly, leaders hadn’t established the necessary culture, systems, and procedures. Only leaders can develop and reinforce a culture that opposes the blame game and makes people feel both comfortable with and responsible for surfacing and learning from failures. They should insist that their organizations develop a clear understanding of what happened—not of “who did it”—when things go wrong. This requires consistently reporting failures, small and large; systematically analyzing them; proactively searching for opportunities to experiment; utilizing widely-known practices like 'chaos engineering' to improve the system's resiliency continuously and finally, design your business-critical systems for high availability in advance.
References:
- Microservices Architecture: https://docs.microsoft.com/en-us/azure/architecture/guide/architecture-styles/microservices
- Harvard Business Review - Learning From Failure: https://hbr.org/2011/04/strategies-for-learning-from-failure
- Engineering for HA (High Availability) in Azure: https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/app-service-web-app/multi-region
- Load balancing without Load Balancers: https://blog.cloudflare.com/cloudflares-architecture-eliminating-single-p/
- How to build a Disaster Recovery (DR) plan: https://www.resolutets.com/how-to-build-an-it-disaster-recovery-plan
- Chaos Engineering: the history, principles, and practice: https://www.gremlin.com/community/tutorials/chaos-engineering-the-history-principles-and-practice/
Comments